Recently, I’ve written about how the English language is evolving, not only globally but also in the context of artificial intelligence. Language has always been a dynamic force, shaped by people, cultures and changing technologies. The rise of generative AI is now accelerating that change in new and sometimes unexpected ways.
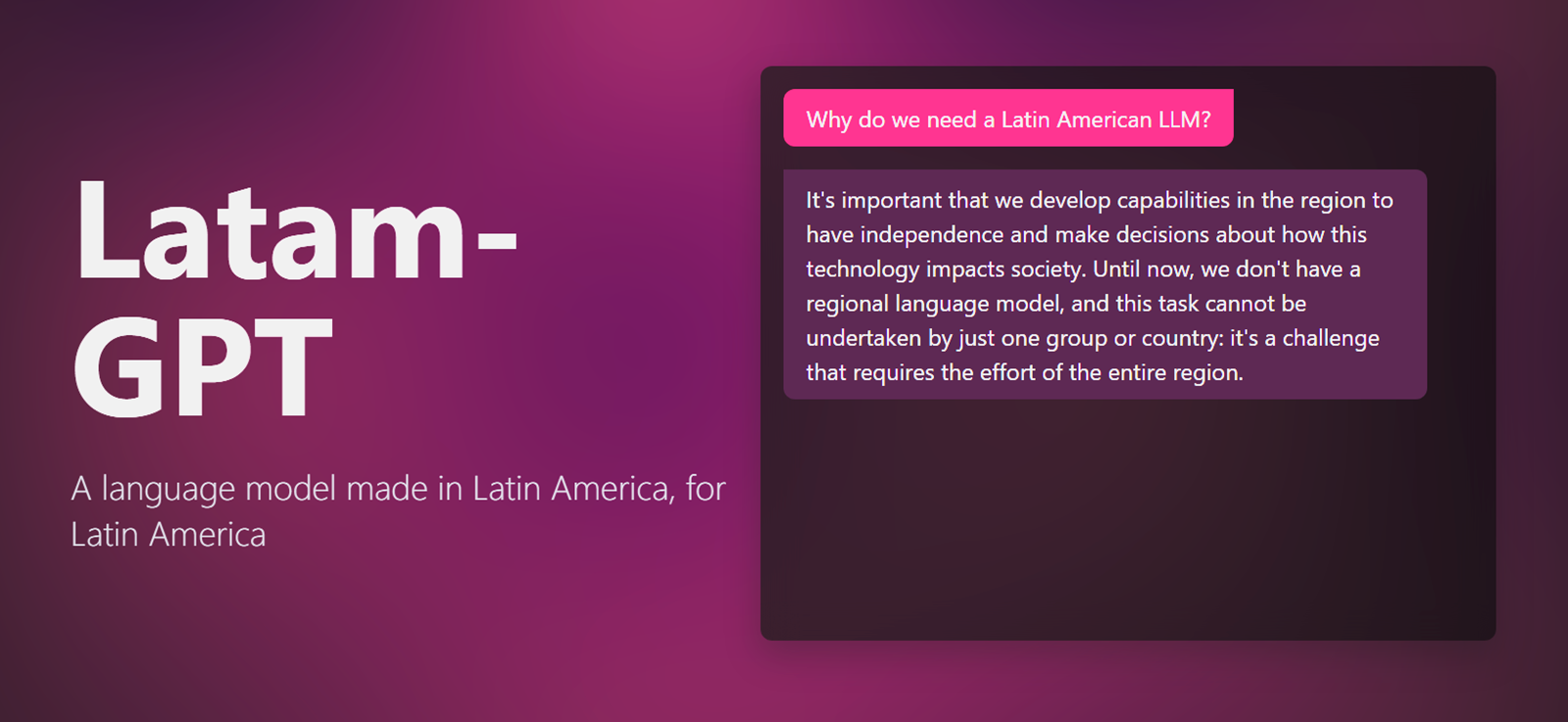
So it was with keen interest that I read a report this week on Rest of World about an ambitious initiative underway in Latin America to build a large language model (LLM) that understands the region’s own cultural and linguistic nuances.
Led by Chile, it’s called Latam-GPT, and it’s being developed by more than 30 institutions across Latin America and the Caribbean.
What Latam-GPT is Trying to Solve
While large language models, including OpenAI's GPT and Meta’s Llama, are trained on a wide range of data in languages other than English, their capability in those languages remains limited, particularly in dialects and local idioms.
The core issue is familiar to anyone who’s used ChatGPT in a language other than English – or even in English but with cultural context that differs from the Anglo-American world. These tools are remarkably capable, but they often fall short when dealing with local idioms, dialects, or geographically specific references.
Latam-GPT seeks to address this by doing something deceptively simple: building a language model in Latin America, for Latin Americans. That means:
- Training the model on locally sourced data – from schools, libraries, and historical texts in the countries of Latin America.
- Including dialects and indigenous languages such as Nahuatl, Quechua and Mapudungun.
- Collaborating across borders – Chile has signed agreements with over 30 partners from Latin America, the US and Spain.
- Making the model open source and publicly accessible from September 2025.
This model isn’t trying to outmatch ChatGPT on general knowledge. Instead, it's focused on cultural fidelity, linguistic accuracy, and social inclusion in the region it aims to serve.
The project demonstrates that Latin America has the technical talent and institutional will to lead AI development on its own terms – something often overlooked in narratives dominated by the US, China and Europe.
The Challenges Ahead
Building a model like this isn’t without significant hurdles, though:
⚠️ Infrastructure limitations – Latam-GPT requires huge computing power, but much of the region lacks the ultra-high-capacity infrastructure seen in the global North.
⚠️ Environmental impact – Training LLMs consumes a great deal of energy and water. While concerns are valid, the team behind Latam-GPT has stated that it uses solar energy and a scalable cloud-based infrastructure to help mitigate environmental costs. In Chile, where the model is based, there’s already concern about the effects on a region hit by long-term drought.
⚠️ Uneven data protection – Privacy laws vary widely across Latin America. What is acceptable in Costa Rica may not be protected in Uruguay, for example, raising legal and ethical questions about data collection.
⚠️ Representation gaps – Despite efforts to include marginalised voices, the project may struggle to meaningfully involve indigenous and migrant communities unless access and participation are deliberately built into the process.
⚠️ Competitive pressure and digital dependency – Chinese-developed DeepSeek offers a powerful, affordable alternative that’s already being deployed in the region. While its efficiency is attractive, widespread adoption could risk entrenching reliance on foreign technology – potentially undermining efforts to build sovereign, culturally aligned AI in Latin America.
Why This Project Matters Globally
Latam-GPT is part of a growing movement of regional AI development. From BharatGPT in India to Sea-Lion in Southeast Asia and UlizaLlama in Africa, Global South countries and communities are beginning to ask a critical question:
What good is a global AI model if it doesn’t understand my world?
In Europe, a different kind of regional AI project is emerging: ChatEurope, a multilingual chatbot and news platform launched by a 15-partner media consortium, led by Agence France-Presse, to improve access to trustworthy European news and combat disinformation. While not a large language model like Latam-GPT, it reflects the same impulse – to root AI tools in local needs, values and public trust.
This is not about rejecting global innovation – it’s about localising it. And that’s a crucial distinction as we move toward a future where AI will mediate more of our interactions, decisions and cultural exchanges.
If nothing else, Latam-GPT should prompt those of us in the English-speaking world to reconsider assumptions about AI’s “universality.” The language we speak, the words we choose, and the stories we tell all come from somewhere. AI models should respect that.
As we build and adopt these tools, let’s not forget the old linguistic truth: meaning doesn’t travel well without context. This emphasis on localisation aligns closely with my ongoing interest in how AI can be shaped to reflect diverse human realities – ethically, inclusively, and with cultural sensitivity.
And in the world of AI, context is culture.
Related Reading:
- Whose Behaviour Does AI Teach? (7 July 2025)
- Whose English Does AI Speak? (12 May 2025)